*Fortune 100개 기업 기준으로 80% 이상이 카프카(Kafka)를 사용 *제조, 은행, 통신 등 다양한 업종에서 높은 비율로 사용 *국내에서도 큰 회사들은 많이 사용
카프카의 배경
MSA(Micro Service Architecture) 구조로 서비스를 운영하면서 여러개의 독립적인 서비스로 나누어지며 서버 간에 상호작용이 많아졌다. → 오버헤드 증가여러개의 독립적인 서비스로 나누어지며 데이터 파이프라인의 복잡도가 증가하였다. 이는 기업에 커다란 기술부채를 불러왔으며, 이러한 기술부채는 유지보수 및 운영에 악영향을 끼친다.
* 마이크로서비스는 완전히 독립적으로 배포가 가능하고, 다른 기술 스택(개발 언어, 데이터베이스 등)이 사용 가능한 단일 사업 영역에 초점을 둔다.
출처 : https://velog.io/@18k7102dy/Apache-Kafka-%EC%95%84%ED%8C%8C%EC%B9%98-%EC%B9%B4%ED%94%84%EC%B9%B4%EB%9E%80서비스의 규모가 거대해짐에 따라 위의 그림과 같이 데이터 파이프라인의 양상이 매우 복잡해졌다.출처 : https://velog.io/@18k7102dy/Apache-Kafka-%EC%95%84%ED%8C%8C%EC%B9%98-%EC%B9%B4%ED%94%84%EC%B9%B4%EB%9E%80데이터 파이프라인을 파편화시키지 않고, 데이터를 중앙 집중화시키는 전략을 채택하여 대용량 데이터를 수집, 처리하고 사용자들이 데이터를 시시간 스트림으로 소비할 수 있도록 처리하였다.
Publish / Subscribe System
출처 : https://needjarvis.tistory.com/599
우측의 Publish-Subscribe 구조를 보면 중앙에 메시징 서버를 두고 발신자와 수신자가 메시지를 보내고 받는 형식이다.
발신자(Publish) 발신 역할은 중앙 서버에 전송만 하고 수신자가 누구인지 알 필요 없다. 그래서 수신자를 정하지 않고 서버에 전송만 하는 구조이다.
수신자(Subscribe) 중앙 서버에 원하는 토픽을 구독한다. 즉, 수신자는 발신자가 누구인지 관심없고, 필요한 메시지만 구독하게 하는 것이다. 이를 통해 Point to Point 구조에 비해 매우 단순해지고 유지보수 및 에러의 발생, 네트워크 트래픽의 장점까지 얻을 수 있다.
출처 : https://soft.plusblog.co.kr/3
발신자 → 데이터를 만들어내는 프로듀서(Producer, 생산자)
수신자 → 소비하는 컨슈머(Consumer, 소비자)
프로듀서와 컨슈머의 중재자 역할을 하는 브로커(Broker, 브로커)
로 구성된 느슨한 결합
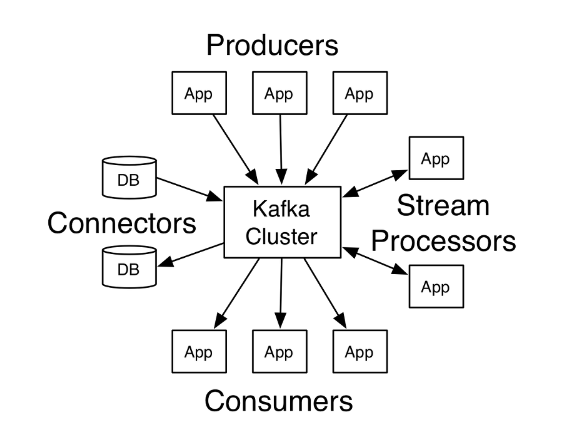
카프카 클러스터로 메시지를 전송할 수 있는 프로듀서와 카프카 클러스터로부터 메시지를 읽어갈 수 있는 컨슈머 클라이언트 API를 제공한다. 그 밖에 데이터 통합을 위한 커넥터(Connector)와 스트림 처리를 위한 스트림즈(Streams) API도 있지만, 크게 보면 프로듀서와 컨슈머의 확장이다.
카프카에서 프로듀서는 특정 토픽(Topic)으로 메시지를 발행할 수 있다. 컨슈머 역시 특정 토픽(Topic)의 메시지를 읽어갈 수 있다. 카프카에서 토픽은 프로듀서와 컨슈머가 만나는 지점이라고 할 수 있다.
카프카는 수평적인 확장(Scale out)을 위해 클러스터를 구성한다. 카프카를 통해 유통되는 메시지가 늘어나면 카프카 브로커의 부담(Load)이 증가하게 되어 클러스터의 규모를 확장할 필요가 있다. 카프카는 여러 브로커들의 클러스터링을 위해 아파치 주키퍼(Apache Zookeeper)를 사용한다.
카프카 클러스터 위에서 프로듀서가 전송한 메시지는 중복 저장(Replication) 되어 장애 상황에서도 고 가용성을 보장하게 된다. 프로듀서가 카프카 클러스터로 메시지를 전송하면 브로커는 또 다른 브로커에게 프로듀서의 메시지를 중복해서 저장한다. 만약 한 브로커에 장애가 생기더라도 중복 저장된 복사본을 컨슈머에게 전달할 수 있으므로 장애 상황에 대비할 수 있다.
소스 어플리케이션과 타겟 어플리케이션 사이의 데이터 파이프라인을 카프카가 추상화시키는 역할을 하기 때문에 둘 간의 의존도는 낮아진다.
2. 카프카는 높은 처리량을 가지고 있기 때문에 실시간 대량의 로그데이터를 처리하는데 적합하다.
카프카는 프로듀서, 컨슈머가 브로커를 통해 데이터를 송수신 할 때, 데이터가 배치의 형태로 묶여서 송수신 되는 특징을 가지고 있다. 데이터가 개별 단위로 파편화 되어 트랜잭션이 맺어지는 것보다 Batch의 형태로 하나로 묶여 트랜잭션이 맺어지면 네트워킹에 있어 비용이 감소한다.
3. 확장성(Scaleability)이 높다.
카프카는 클러스터 단위로 묶어서 관리할 수 있다는 특징이 있다. 따라서 서비스에 트래픽이 몰릴 경우, 클러스터의 노드(Node)개수를 늘려 수평 확장하고, 트래픽이 적어질 경우에는 클러스터의 노드(Node) 개수를 줄여 유연하게 트래픽을 처리할 수 있다.
4. 영속성을 지니고 있다. 따라서 카프카 클러스터(Kafka Cluster)에 장애가 발생하더라도 복구가 쉽다.
Kafka는 데이터를 Topic에 담아 저장을 하고, 데이터를 저장하기 위해 OS 레벨에서의 파일 시스템을 이용한다. 운영체제에서는 파일의 입출력 성능을 향상시키기 위해서 Page Cache 영역을 메모리에 따로 생성하여 page 단위로 메모리를 할당시킨다. 운영체제는 페이지 캐시 메모리 영역을 사용해서 한번 읽은 파일 내용은 메모리에 임시 저장 해두었다가 나중에 다시 사용하는 방식을 채택한다. Kafka는 OS의 이러한 시스템을 이용하여 데이터를 저장하는데 이러한 특성 덕분에 데이터의 처리 속도가 높고, 일시적인 장애가 발생하더라도 프로세스를 재시작해서 데이터를 다시 처리할 수 있다.