고정 헤더 영역
상세 컨텐츠
본문
캐싱 전략
웹 서비스 환경에서 시스템 성능 향상을 위해 사용하는 기술. 캐시(Cache)는 메모리(RAM)를 사용함으로써 데이터베이스보다 훨씬 빠르게 데이터를 응답할 수 있어 이용자에게 빠르게 서비스를 제공할 수 있다.
메모리를 사용하기에 데이터를 모두 캐시에 저장한다면 용량 부족 현상이 일어나 시스템에 영향을 주게 된다.
* 일반적으로 메모리의 용량은 16-32G 이므로
캐시를 사용하기에 적합한 데이터 특성
- 자주 조회되는 데이터
- 결과값이 자주 변동되지 않고, 일정한 데이터
- 조회하는데 연산이 필요한 데이터
#용어 정리
더보기
Cache Hit : 캐시 스토어(redis)에 데이터가 있을 경우 바로 가져옴
Cache Miss : 캐시 스토어(redis)에 데이터가 없을 경우 DB에서 가져옴
캐시 이용시 주의 해야할 문제로 데이터 정합성 문제와 성능 문제가 있다.
데이터 정합성이란 어느 한 데이터가 캐시와 데이터베이스 두 곳에서 같은 데이터임에도 불구하고 데이터 정보값이 서로 다른 현상을 말한다.
성능 문제로는 캐시 데이터의 수명 관련 문제이다. 모든 데이터를 지워지지 않고 평생 캐시 저장소에 저장하고 있는 것은 성능 문제를 야기한다.
그렇기 때문에 캐시 만료 정책을 적절하게 설정하고 오랜 시간이 지난 데이터는 캐시 저장소에서 제거될 수 있도록 해야 한다.
캐싱 전략을 세울 때는 적절한 캐시 읽기 전략(Read Cache Strategy)과 캐시 쓰기 전략(Write Cache Strategy)을 통해, 캐시와 데이터베이스 간 정합성 문제와 성능적인 문제를 고려하며 전략을 세워야 한다.
캐시 읽기 전략(Read Cache Strategy)
Look Aside Pattern(Cache Aside Pattern)
데이터 조회시 우선적으로 캐시에 저장된 데이터가 있는지 확인하는 전략. 만약, 캐시에 데이터가 없을 경우 데이터베이스를 조회한다.

- Cache Store에 검색하는 데이터가 있는지 확인 - cache hit
- Cache Store에 없을 경우 데이터베이스에서 데이터 조회 - cache miss
- 데이터베이스에서 조회해 온 데이터를 Cache Store에 업데이트
특징 :
- 반복적인 읽기가 많은 호출에 적합하다.
- 캐시와 데이터베이스가 분리되어 가용되기 떄문에 원하는 데이터만 별도로 구성하여 캐시에 저장한다.
- 캐시와 데이터베이스가 분리되어 가용되기 때문에 캐시 장애가 발생하더라도 데이터베이스에서 데이터를 가져올 수 있어 서비스 자체에 문제가 없다. 하지만, 캐시에 Connection이 많았다면, 순간적으로 데이터베이스로 몰려 부하가 발생한다.
- Cache Store와 데이터베이스 간 정합성 유지 문제가 발생할 수 있어, 초기 조회 시 무조건 데이터베이스를 호출해야 하므로 단건 호출 빈도가 높은 서비스에 적합하지 않다.

Cache Warming
더보기
Cache Warming
미리 캐시(Cache)로 데이터베이스의 데이터를 넣어두는 작업을 의미한다.
이 작업을 수항하지 않을 경우 서비스 초기에 트래픽이 급증할 경우, Cache Miss가 발생하여 데이터베이스 부하가 급증할 수 있다.(Thundering Herd)
캐시 자체는 용량이 작아 무한정으로 데이터를 가지고 있을 수 없으므로 일정 시간이 지나면 Expire된다. 그러면 다시 Thundering Herd가 발생할 수 있기 때문에 캐시의 TTL을 조정해야 한다.
* TTL (Time To Live) : 데이터 유효 기간
Read Through Pattern
Look Aside(Cache Aside)와 비슷하지만 데이터 동기화를 라이브러리 또는 캐시 제공자에게 위임하는 방식이라는 차이가 있다.
Read Through Pattern은 캐시와 데이터베이스가 일렬로 배치되며, Cache Miss가 발생하면 데이터베이스에서 누락된 데이터를 로드하고 캐시를 업데이트하고 이를 애플리케이션에 반환한다.
Cache Aside Pattern과의 차이점은 애플리케이션이 캐시를 채우는 역할을 하는지 여부에 따라 있다.

- Cache Store에 검색하는 데이터가 있는지 확인 - Cache Hit
- Cache Store에 없을 경우, 캐시(Cache)에서 데이터베이스에 데이터를 조회하여 자체 업데이트 - Cache Miss
- Cache Store에서 데이터를 가져옴.
특징 :
- 데이터를 조회하는데 있어 전체적으로 속도가 느리다.
- 직접적인 데이터베이스 접근을 최소화하고 Read에 대해 소모되는 자원을 최소화할 수 있다.
- 데이터 조회를 전적으로 캐시에만 의지하므로, Cache Store가 문제가 생길 경우, 서비스에 문제가 발생하여, 전체 서비스가 중단될 수 있으므로, Cache Store 를 Replication 또는 Cluster로 구성하여 가용성을 높여야 한다.
- Cache Store 와 데이터베이스 간의 데이터 동기화가 항상 이루어져 데이터 정합성 문제에서 벗어날 수 있다.
- 읽기가 많은 워크로드에 적합하다.
- 초반에 Cache Warming을 수행하는 것이 좋다.
캐시 쓰기 전략(Cache Write Strategy)
Write Back Pattern (Write Behind Pattern)
캐시(Cache)와 데이터베이스 동기화를 비동기로 하는 방법이며 동기화 과정이 생략되기 때문에 쓰기 작업이 많은 경우에 적합하다. 캐시에서 일정 시간 또는 일정량의 데이터를 모아놓았다가 한번에 데이터베이스에 업데이트 하기 때문에 쓰기 비용을 절약할 수 있다.
캐시(Cache)에서 데이터베이스로 데이터를 업데이트 하기 전에 장애가 발생하면 데이터가 유실될 수 있다.
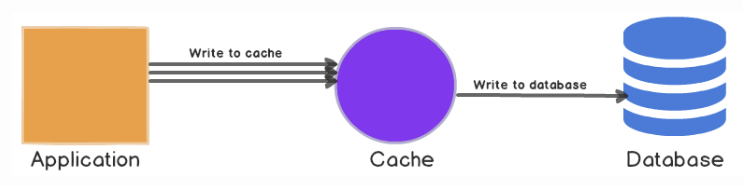
- 모든 데이터를 Cache Store에 저장
- 일정 시간 또는 일정량이 되면 데이터베이스에 저장
특징 :
- 캐시와 데이터베이스 동기화를 비동기방식으로 처리하기 때문에 동기화 과정이 생략
- 캐시에 모아서 데이터베이스에 쿼리하기 때문에 쓰기 쿼리 회수 비용과 부하를 줄일 수 있다.
- 캐시에 데이터를 데이터베이스로 옮기기 전에 캐시 장애가 발생하면 데이터 유실이 발생할 수 있다.
- 데이터베이스에 장애가 발생하더라도 지속적인 서비스를 제공할 수 있다.
- 쓰기가 빈번하면서 읽기하는데 많은 양의 리소스(Resource)가 소모되는 서비스에 적합하다.
- 데이터의 정합성 확보
# 캐시에 Replication이나 Cluster 구조를 적용함으로써 Cache 서비스의 가용성을 높이는 것이 좋으며, 캐시 읽기 전략인 Read-Through 와 결합하면 가장 최근에 업데이트 된 데이터를 항상 캐시에서 사용할 수 있는 혼합 워크로드에 적합하다.
Write Through Pattern
데이터를 데이터베이스에 저장할 때마다 캐시에 데이터를 추가하거나 업데이트 한다. 이로 인해 캐시의 데이터는 항상 최신 상태로 유지할 수 있지만, 쓰지 않는 데이터도 저장되기 때문에 리소스(Resource)가 낭비된다.
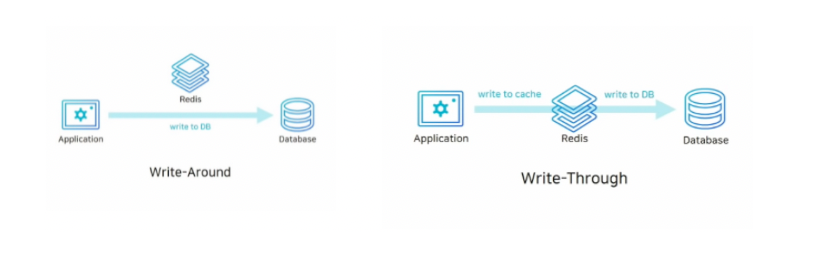
- 데이터베이스에 저장할 데이터가 있으면 우선 Cache Store에 저장
- 그리고 바로 Cache Store에서 데이터베이스로 저장
특징 :
- Read Through와 마찬가지로 데이터베이스 동기화 작업을 캐시에게 위임
- 캐시(Cache)와 데이터베이스가 항상 동기화되어 있어, 캐시의 데이터는 항상 최신 상태로 유지한다.
- 캐시(Cache)와 백업 저장소에 업데이트를 같이 하여 데이터 일관성을 유지할 수 있어서 안정적이다.
- 데이터 유실이 발생하면 안되는 상황에 적합
- 자주 사용되지 않는 불필요한 리소스 저장
- 매 요청마다 쓰기가 두 번 발생하게 됨으로써 빈번한 쓰기, 수정이 발생하는 서비스에서는 성능 이슈 발생
- 기억장치 속도가 느릴 경우, 데이터를 기록할 때 CPU가 대기하는 시간이 필요하기 때문에 성능 감소
# Write Through Pattern 과 Write Back Pattern 둘 다 모두 자주 사용되지 않는 데이터가 저장되어 리소스 낭비가 발생되는 문제점을 안고 있기 때문에, 이를 해결하기 위해 TTL을 꼭 사용하여 사용되지 않는 데이터를 반드시 삭제해야 한다. *Expire 명령어
Write Through Pattern 과 Read Through Pattern 을 함께 사용하면, 캐시의 최신 데이터 유지와 더불어 데이터의 정합성을 얻을 수 있다.
대표적인 예로 AWS의 DynamoDB Accelerator(DAX)가 있다.

DynamoDB Accelerator(DAX) 는 읽기 / 쓰기 캐시의 좋은 예이다. DynamoDb 및 애플리케이션과 인라인으로 배치된다. DynamoDB에 대한 읽기 및 쓰기는 DAX를 통해 수행할 수 있다.
출처 : https://wnsgml972.github.io/database/2020/12/13/Caching/
Write Around Pattern
데이터는 데이터베이스에 직접 기록되며, 읽은 데이터만 캐시에 저장된다.
Write Around Pattern 은 Read-Through와 결합될 수 있으며, Cache-Aside와도 결합될 수 있다. 데이터가 한 번 쓰여지고, 읽기가 적은 경우 좋은 성능을 보인다. 예를 들어, 실시간 로그 또는 채팅방 메시지가 있다.
- 모든 데이터 데이터베이스에 저장
특징 :
- 속도가 빠르다. Write Through 보다 빠름.
- 모든 데이터를 데이터베이스에 저장. 캐시를 갱신하지 않음.
- Cache Miss가 발생하는 경우에만 데이터베이스와 캐시에도 데이터를 저장한다.
- Cache Miss가 발생하기 전에 데이터베이스에 저장된 데이터가 수정되었을 때, 사용자가 조회하는 캐시와 데이터베이스간에 데이터 불일치가 발생한다.
따라서, 데이터베이스에 저장된 데이터가 수정, 삭제될 때마다, 캐시 또한 삭제하거나 변경해야 하며, 캐시의 Expire를 짧게 조정하는 방식으로 대처해야 한다.
# Write Around Pattern 은 주로 Look Aside Pattern, Read Through Pattern 과 결합해서 사용된다.
# 데이터가 한 번 쓰여지고, 자주 읽히지 않는 상황에서 좋은 성능을 제공한다.
캐시 전략 조합
Look Aside + Write Around 조합
- 가장 일반적으로 자주 쓰이는 조합
Read Through + Write Around 조합
- 항상 데이터베이스에 쓰고, 캐시에서 읽을 때 항상 데이터베이스에서 먼저 읽어오므로 데이터 정합성 이슈에 대한 완벽한 안전 장치를 구성할 수 있음.
Read Through + Write Through 조합
- 데이터를 쓸 때 항상 캐시에 먼저 쓰므로, 읽어올 때 최신 캐시 데이터 보장
- 데이터를 쓸 때 항상 캐시에서 데이터베이스로 보내므로, 데이터 정합성 보장
[Cache] 캐싱 전략2 바로가기
https://hojinjeong.tistory.com/286
참고 :
더보기
[REDIS] 📚 캐시(Cache) 설계 전략 지침 💯 총정리
Redis - 캐시(Cache) 전략 캐싱 전략은 웹 서비스 환경에서 시스템 성능 향상을 기대할 수 있는 중요한 기술이다. 일반적으로 캐시(cache)는 메모리(RAM)를 사용하기 때문에 데이터베이스 보다 훨씬 빠
inpa.tistory.com
https://wnsgml972.github.io/database/2020/12/13/Caching/
Caching 전략 소개 및 사용 예제
캐싱 전략이란? “캐싱 전략”은 최근 웹 서비스 환경에서 시스템 성능 향상을 위해 가장 중요한 기술입니다. 캐시는 메모리를 사용함으로 디스크 기반 데이터베이스 보다 훨씬 빠르게 데이터
wnsgml972.github.io
https://bcp0109.tistory.com/364
Cache 전략
Overview What is Caching ? 글을 참고하여 캐시 전략에 대해 정리했습니다. 1. Cache 란? 위키 백과에는 이렇게 나와 있습니다. 데이터나 값을 미리 복사해 놓는 임시 장소를 가리킨다. 캐시는 캐시의 접
bcp0109.tistory.com
[Redis] 캐시란? 캐싱전략? 알고 써보자!
사용자에 입장에서 데이터를 더 빠르게, 더 효율적으로 액세스를 할 수 있는 임시 데이터 저장소를 뜻한다. 대부분의 어플리케이션에서 속도 향상을 위해 캐시를 사용한다고 한다.캐시 저장소
velog.io
https://www.youtube.com/watch?v=92NizoBL4uA
'DATABASE' 카테고리의 다른 글
| [MYSQL] SELECT 결과 UPDATE 시키기 (0) | 2023.08.10 |
|---|---|
| [Cache] 캐싱 전략2 (0) | 2023.05.25 |
| [데이터베이스] 인덱스(Index) (0) | 2023.05.14 |
| [데이터베이스] 식별관계 & 비식별관계 (0) | 2023.05.11 |
| [데이터베이스] MySQL 이벤트 스케줄러 (0) | 2023.05.11 |




